Best Gunicorn Worker Types for FastAPI
Published on March 2, 2026
By ToolsGuruHub
You've read the docs. You know you should use Gunicorn in production. You run gunicorn main:app -w 4 and everything seems to work - until you realize your FastAPI endpoints are throwing RuntimeError: no running event loop. Or your API handles 50 requests per second instead of the 500 you expected. Or WebSocket connections just don't work.
The reason is almost always the same: you're using the wrong Gunicorn worker type. Gunicorn supports multiple worker classes, and picking the right one for FastAPI isn't optional - it's the difference between a working deployment and a broken one.
Let's go through every worker type Gunicorn offers, what each one does, and which one you actually need for FastAPI.
Gunicorn Worker Types at a Glance
Gunicorn supports four main worker types. Here's the quick overview before we dive deep:
| Worker Type | Class Name | Concurrency Model | Works with FastAPI? |
|---|---|---|---|
| Sync | sync (default) | One request per worker, blocking | No |
| Threaded | gthread | Multiple threads per worker | Partially |
| Gevent | gevent | Green threads (cooperative) | No |
| Uvicorn | uvicorn.workers.UvicornWorker | Async event loop | Yes - recommended |
If you just want the answer: use uvicorn.workers.UvicornWorker. If you want to understand why, keep reading.
The Default: Sync Workers
gunicorn main:app -w 4
# equivalent to:
gunicorn main:app -w 4 -k sync
How It Works
The sync worker is Gunicorn's default. Each worker handles one request at a time. Worker receives request -> processes it -> sends response -> ready for next request. If processing takes 200ms, that worker handles at most 5 requests per second.
Why It Doesn't Work with FastAPI
FastAPI is built on Starlette, which is an ASGI framework. ASGI requires an async runtime - an event loop. Gunicorn's sync worker speaks WSGI, not ASGI. When you run FastAPI with a sync worker:
gunicorn main:app -w 4 -k sync
Gunicorn tries to call your FastAPI app as a WSGI callable. FastAPI isn't WSGI. The result depends on the FastAPI version and configuration, but you'll typically see errors or unexpected behavior because the async machinery FastAPI depends on simply isn't available.
Verdict: Do not use with FastAPI. Sync workers are for WSGI frameworks (Django, Flask).
Threaded Workers (gthread)
gunicorn main:app -w 4 -k gthread --threads 4
How It Works
Each worker spawns multiple threads. With -w 4 --threads 4, you get 4 processes × 4 threads = 16 concurrent request handlers. Each thread handles one request at a time, but threads can run concurrently (within GIL constraints) for I/O-bound work.
Why It Doesn't Work Well with FastAPI
Same fundamental problem as sync workers - gthread is a WSGI worker type. It doesn't provide an async event loop, which FastAPI's ASGI interface requires.
FastAPI can technically run some code under WSGI-like wrappers because Starlette has some compatibility layers, but you lose:
- All async def endpoint benefits (they won't actually run asynchronously)
- WebSocket support
- ASGI middleware
- Server-Sent Events and streaming responses
- Any library that depends on asyncio
You'd be running an async framework synchronously - defeating the entire purpose of choosing FastAPI.
Verdict: Not recommended for FastAPI. If you're using gthread, you might as well use Flask.
Gevent Workers
gunicorn main:app -w 4 -k gevent
How It Works
Gevent uses monkey-patching to replace Python's standard library I/O operations with cooperative greenlets. This gives you thousands of lightweight "green threads" per worker that yield control when they hit I/O operations. It's a form of concurrency that predates Python's asyncio.
# Gevent monkey-patches the standard library at import time
from gevent import monkey
monkey.patch_all()
Why It Doesn't Work with FastAPI
Gevent and asyncio don't play well together. They're two different concurrency models:
- Gevent: Cooperative multitasking via greenlets and monkey-patching
- asyncio: Cooperative multitasking via coroutines and async/await
When you run FastAPI under gevent:
- Gevent monkey-patches the standard library
- FastAPI tries to create an asyncio event loop
- The monkey-patched event loop may conflict with gevent's scheduler
- You get unpredictable behavior - deadlocks, race conditions, or subtle correctness bugs
Some developers have gotten gevent + FastAPI to work in limited cases, but it's fragile, unsupported, and defeats the purpose. FastAPI was designed for native asyncio, not gevent's greenlet model.
Verdict: Do not use with FastAPI. Gevent is excellent for WSGI apps that need concurrency without rewriting code to be async (e.g., Flask apps with many I/O calls). It's the wrong tool for ASGI apps.
UvicornWorker - The Right Choice
gunicorn main:app -w 4 -k uvicorn.workers.UvicornWorker
How It Works
Each Gunicorn worker starts a full Uvicorn server instance with its own asyncio event loop. The worker:
- Creates an asyncio event loop (via uvloop if installed)
- Loads your FastAPI app as an ASGI application
- Handles HTTP requests asynchronously using coroutines
- Returns responses via the ASGI protocol
Gunicorn manages the worker processes (spawn, monitor, restart), while Uvicorn inside each worker handles the actual async request processing.
Why It's the Right Choice for FastAPI
- ASGI native: Speaks the same protocol FastAPI expects
- Full async support: All async def endpoints run on a real event loop
- WebSocket support: ASGI handles long-lived connections natively
- Streaming and SSE: Event loop supports streaming responses
- High concurrency: Each worker handles hundreds of concurrent I/O-bound requests
- Compatible ecosystem: Works with asyncpg, httpx, aioredis, and every async library
Production Configuration
# gunicorn_config.py
import multiprocessing
bind = "0.0.0.0:8000"
workers = multiprocessing.cpu_count() * 2 + 1
worker_class = "uvicorn.workers.UvicornWorker"
# Timeouts
timeout = 120
graceful_timeout = 30
keepalive = 5
# Worker recycling (memory leak protection)
max_requests = 10000
max_requests_jitter = 1000
# Logging
accesslog = "-"
errorlog = "-"
loglevel = "info"
gunicorn main:app -c gunicorn_config.py
Verdict: This is the standard, recommended, and well-supported way to run FastAPI in production.
Performance Comparison: What the Numbers Look Like
To make this concrete, here's what you can expect from a typical FastAPI app (JSON API with async database queries) on a 4-core machine:
| Worker Type | Config | Concurrent Requests | Requests/sec | Memory |
|---|---|---|---|---|
| sync | -w 9 -k sync | 9 (one per worker) | ~45 | ~450MB |
| gthread | -w 4 -k gthread --threads 4 | 16 (threads) | ~80 | ~500MB |
| gevent | -w 4 -k gevent | N/A (incompatible) | N/A | N/A |
| UvicornWorker | -w 4 -k uvicorn.workers.UvicornWorker | 1000+ | ~500 | ~320MB |
These numbers are illustrative for a typical I/O-bound API. Your actual results depend on endpoint complexity, database latency, and hardware.
The UvicornWorker handles an order of magnitude more concurrent requests because async I/O doesn't block workers while waiting on databases or external APIs.
Worker Count: How Many UvicornWorkers?
The Formula
For async workers, the standard formula (2 × CPU) + 1 is a starting point:
import multiprocessing
workers = multiprocessing.cpu_count() * 2 + 1
But async workers are fundamentally different from sync workers. A sync worker can handle 1 request at a time. An async worker can handle hundreds. So:
| Workload | Recommended Workers | Why |
|---|---|---|
| Pure I/O (DB, HTTP calls) | CPU_CORES + 1 | Event loops handle concurrency; more workers waste memory |
| Mixed I/O + CPU | (2 × CPU_CORES) + 1 | Extra workers absorb CPU spikes without blocking other event loops |
| Heavy CPU per request | (2 × CPU_CORES) + 1 or more | CPU work blocks the event loop; need more workers to compensate |
How to Tune
- Start with CPU_CORES * 2 + 1
- Monitor CPU utilization and response latency under load
- If CPU is underutilized and response times are low -> reduce workers (save memory)
- If response times spike under load -> add workers (if CPU headroom exists)
- If memory is tight -> reduce workers or lower max_requests for faster recycling
Common Mistakes
Mistake 1: Using Default Worker Type
# This uses sync workers - broken for FastAPI
gunicorn main:app -w 4
Always specify -k uvicorn.workers.UvicornWorker. Never rely on the default.
Mistake 2: Too Many Workers
# 32 workers on a 4-core machine = wasted memory
gunicorn main:app -k uvicorn.workers.UvicornWorker -w 32
Each worker consumes 50-100MB+ of RAM. 32 workers = 1.6-3.2GB just for worker processes. With async workers, you rarely need more than (2 × CPU_CORES) + 1 because each worker handles hundreds of concurrent requests internally.
Mistake 3: Mixing Gevent and Async Code
# This is a recipe for deadlocks
from gevent import monkey
monkey.patch_all()
# Then importing FastAPI, which uses asyncio
from fastapi import FastAPI
If you see gevent and asyncio in the same project, something is wrong. Pick one concurrency model and stick with it.
Mistake 4: Blocking the Event Loop in Async Workers
Even with the right worker type, you can kill performance by blocking the event loop:
import time
@app.get("/slow")
async def slow_endpoint():
time.sleep(5) # BLOCKS THE ENTIRE EVENT LOOP
return {"result": "done"}
Every other request on that worker waits 5 seconds. Use await asyncio.sleep(5) or asyncio.to_thread(time.sleep, 5) for blocking operations:
import asyncio
@app.get("/slow")
async def slow_endpoint():
await asyncio.sleep(5) # Yields control to the event loop
return {"result": "done"}
Mistake 5: Using sync Workers for "Compatibility"
Some developers choose sync workers because their codebase has synchronous libraries. The correct fix isn't to downgrade your server - it's to either:
- Use async alternatives (httpx instead of requests, asyncpg instead of psycopg2)
- Run sync code in a thread pool: await asyncio.to_thread(sync_function)
- Use FastAPI's built-in handling: define the endpoint as def (not async def) and FastAPI will automatically run it in a thread pool
# FastAPI automatically runs this in a thread pool
@app.get("/users")
def get_users():
# Sync code is fine here - FastAPI handles it
return db.query(User).all()
Decision Flowchart
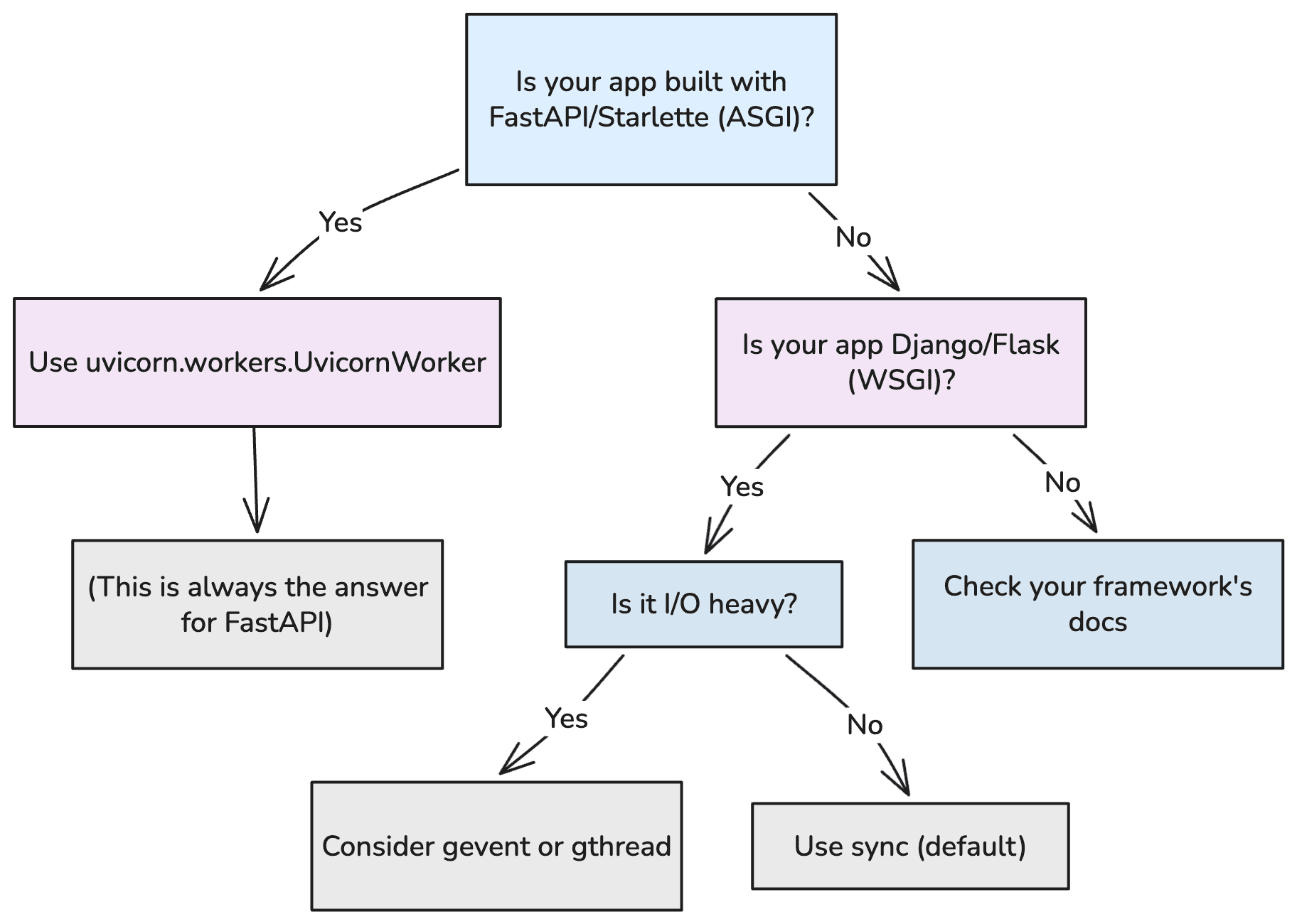
For FastAPI, there is exactly one correct answer: uvicorn.workers.UvicornWorker. The other worker types exist for other frameworks. Using them with FastAPI is either broken (sync, gevent) or suboptimal (gthread).
FAQ
Can I use uvicorn.workers.UvicornH11Worker instead?
`UvicornH11Worker** uses the pure-Python h11 HTTP parser instead of the C-based httptools. It's slower but has no C dependencies. Use it only if you can't install httptools (rare). For production, always prefer UvicornWorker with uvicorn[standard] installed for maximum performance.
What about using uvicorn --workers 4 instead of Gunicorn?
It works, but you lose Gunicorn's mature process management: max_requests with jitter, TTIN/TTOU signals for dynamic scaling, server hooks, and battle-tested crash recovery. For production VMs, Gunicorn is the better process manager. For a detailed comparison, see our Gunicorn + Uvicorn together guide.
Does the worker type affect WebSocket performance?
Yes. Only UvicornWorker supports WebSockets because it's the only worker type that speaks ASGI. Sync, gthread, and gevent workers speak WSGI, which has no WebSocket support.
Should I use --preload with UvicornWorker?
--preload loads your application before forking workers. This saves memory (shared pages via copy-on-write) and catches import errors early. But it can cause issues with some async libraries that initialize connections or event loops at import time. Test it - if it works with your app, use it:
gunicorn main:app -k uvicorn.workers.UvicornWorker -w 4 --preload
What if I need to run sync and async code in the same app?
FastAPI handles this natively. Define sync endpoints with def and async endpoints with async def. FastAPI runs def endpoints in a thread pool automatically. Use UvicornWorker regardless - it handles both patterns correctly.
# Async endpoint - runs on the event loop
@app.get("/async-users")
async def get_users_async():
return await async_db.fetch_all("SELECT * FROM users")
# Sync endpoint - FastAPI runs this in a thread pool
@app.get("/sync-users")
def get_users_sync():
return sync_db.execute("SELECT * FROM users").fetchall()
Both work correctly under UvicornWorker. No configuration changes needed.